

Standardizing Features Without Breaking Your Pipeline
A More Coherent Way to Standardize Features in Quantitative Pipelines

In quantitative trading, standardizing features is almost a reflex.
It helps stabilize distributions, improves model convergence, and makes signals comparable across time. Whether you work with returns, volatility, or engineered indicators, scaling is everywhere.
In practice, most pipelines rely on StandardScaler from scikit-learn.
That is perfectly acceptable in research. But as soon as a pipeline becomes more serious, this setup starts to create unnecessary friction.
1. The Real Issue Is Not the Math
The problem is not standardization itself. The problem is fragmentation.
A typical quant stack quickly becomes a mix of unrelated components. Features may come from one library, transformations from another, and scaling from yet another. You might compute signals with Oryon, apply an operator from SciPy, then standardize everything with scikit-learn.
Each piece works in isolation. But the overall system becomes harder to reason about.
You end up mixing different APIs, different update models, and different assumptions about how computations should behave through time. In a notebook, this may still feel manageable. In a real feature pipeline, it becomes cumbersome.
2. A More Coherent Design
The idea behind the scalers added in Oryon is straightforward: scaling should behave exactly like any other feature. Instead of treating it as a separate preprocessing step, it becomes part of the pipeline itself, built on the same assumptions, with the same interface.
This means:
same update logic
same state management
same behavior in research and live
A rolling standard deviation, for instance, is no longer something you compute “outside” your pipeline. It is a feature, updated incrementally.
3. From Raw Prices to Standardized Signal
Below is a pipeline that computes several market features and standardizes them directly inside Oryon using a rolling z-score.
from oryon.datasets import load_sample_bars
from oryon import FeaturePipeline
from oryon.features import Sma, ParkinsonVolatility, Correlation, ShannonEntropy, Adf
from oryon.scalers import RollingZScore
from oryon.adapters import run_features_pipeline_pandas
# Import sample data (OHLCV bars)
df = load_sample_bars()
# Create the features list
features_list = [
Correlation(inputs=["close", "volume"], window=30, outputs=["close_volume_corr_30"]),
ParkinsonVolatility(inputs=["high","low"], window=50, outputs=["close_pvol_50"]),
Adf(inputs=["close"], window=100, outputs=["close_adf_100", "close_adf_pval_100"])
]
# Create the scalers list to apply z-score to all the wanted features
scalers_list = [RollingZScore(inputs=[col], window=2000, outputs=[f"z_{col}"]) for col in [
"close_volume_corr_30", "close_pvol_50", "close_adf_pval_100"
]]
# Combine both list
features_list.extend(scalers_list)
# Create the pipeline object (that can run to on live trading)
pipe = FeaturePipeline(features_list, input_columns=["close", "high", "low", "volume"])
# Run the pipeline on the sample data
df_features = run_features_pipeline_pandas(pipe, df)What matters here is not only the rolling normalization itself. It is the fact that the scaler is defined exactly like any other component in the pipeline.
There is no handoff to another library, no separate preprocessing object to maintain, and no conceptual break between feature computation and feature standardization.
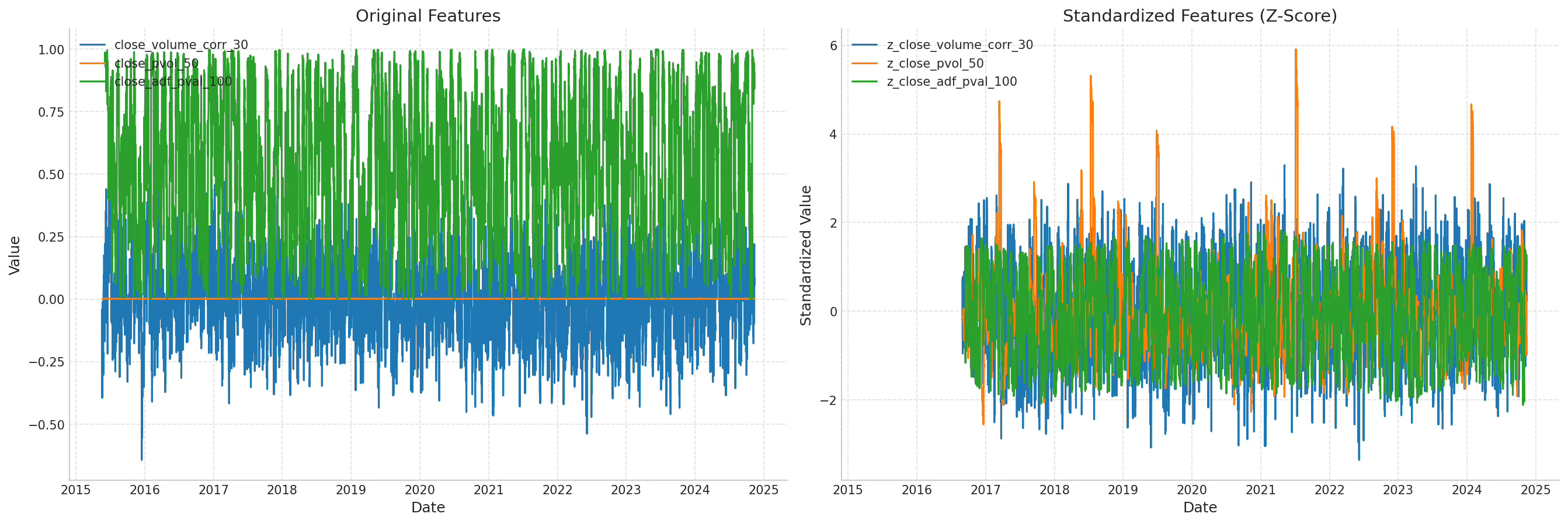
The chart says it all: before scaling, the variables do not really live in the same space. After scaling, they do.
4. Why This Matters
A quant pipeline should not feel like an assembly of disconnected utilities.
As soon as features, operators, and scalers obey different conventions, every extension becomes slightly more fragile. The code becomes harder to read, harder to debug, and harder to move from research to something more robust.
Keeping standardization inside Oryon solves a very practical problem: it removes one more external dependency from the feature workflow and replaces it with a component that behaves exactly like the rest of the system.
The gain is not only speed, even if the implementation is also significantly faster. The deeper gain is consistency.
If you are interested in building cleaner research pipelines, with feature engineering components that are designed to work together rather than coexist by accident, Oryon is exactly the kind of framework worth exploring.
Oryon is now available in beta.
If you want to take a closer look at the library and its design, you can explore it directly on GitHub.
And if you find it useful, consider adding a star. it helps more than it seems.