

The Unsexy Step That Saves You Months (3/8)
Clean, structured, and reproducible data is not optional , it's the foundation of your strategy.

In the previous newsletter, we explored Idea Generation, how to turn raw insights from your data into trading hypotheses worth testing. That phase was about asking good questions, spotting patterns, and building a backlog of possible strategies.
Now it’s time for Data Processing, the often-overlooked step between your idea and your strategy.
Before jumping into backtests or building full systems, you need to make sure your data is ready, clean, consistent… and reproducible. That means thinking not just about the backtest, but also the live trading conditions you’ll face.
In the next newsletter, we’ll get to the real strategy design: entries, exits, sizing rules. But for now, we’re laying the technical foundation. Because if your data is broken or unavailable in production, it doesn’t matter how good your logic is.
Let’s get into it.
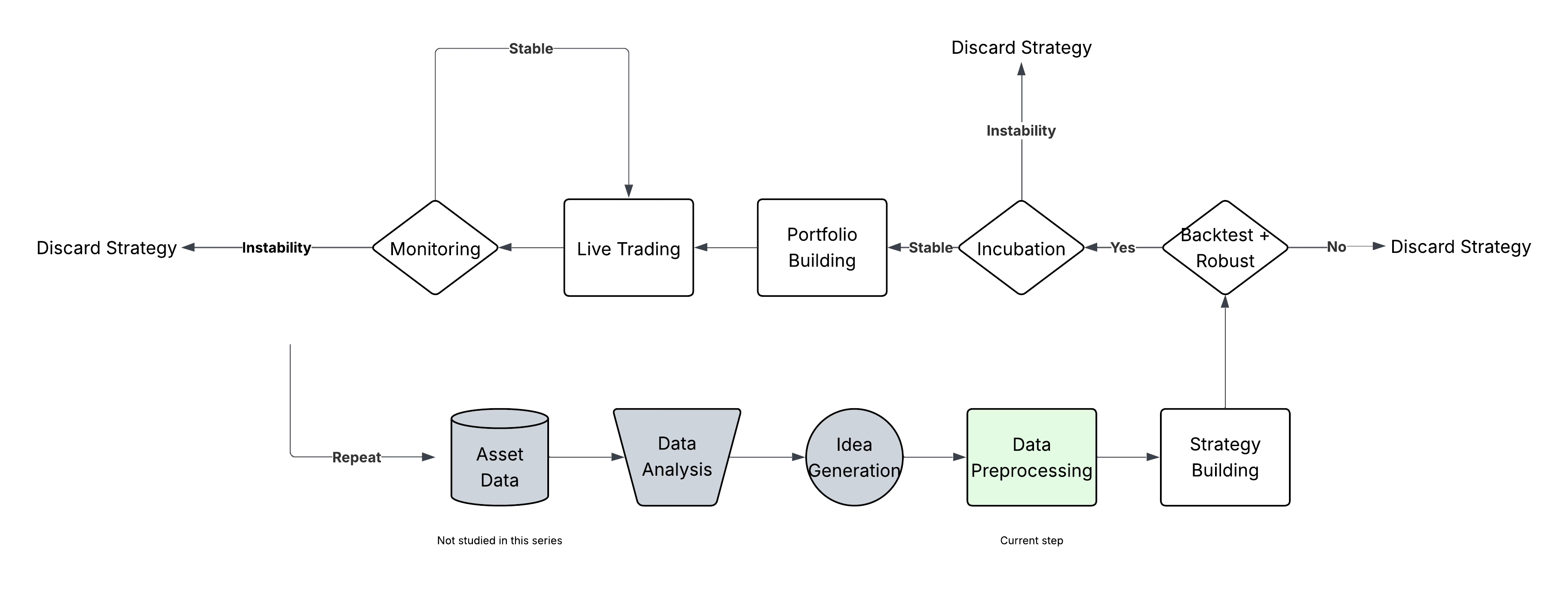
1. From Idea to Implementation Requirements
You probably have a few ideas from your earlier research, maybe volatility tends to spike before large moves, or momentum only works after high volume. The first step now is to pick one hypothesis to turn into a full strategy.
That doesn’t mean the other ideas go to waste. You’ll come back to them later and iterate our process. But for now, focus on developing a single strategy end to end.
Once you’ve selected your idea, it’s time to list everything you’ll need to test it:
What data is required? (price, volume, order book, options…)
What level of granularity? (minute, daily, tick…)
What derived features or indicators will you compute?
And most importantly: can you access these same data in real-time?
This is where many people mess up. They build great backtests using exotic datasets, only to realize later those same inputs are unavailable, delayed, or unaffordable when trading live.
I’ve made that mistake myself. I once found a dataset with deep tick-level futures data, full of microstructural details. It gave me great results… until I tried to go live and discovered it cost $899/month. That was more than I was making from the strategy. End of story.
If I had checked that upfront, I would’ve saved weeks of work. So now, one of my first steps is always: Can I get this in real time? If the answer is no, I either drop the idea or find a proxy I can use.
This step may feel like admin work, but it’s not. It’s about making sure you’re building something that can survive past the notebook.
2. Standardizing and Structuring Your Data
Before you can backtest or build anything, your data needs to be clean, consistent, and ready to use.
Start with the basics:
Missing values: Interpolate, fill, or drop, but don’t ignore them.
Outliers: Investigate them. Sometimes they’re errors, sometimes they’re edge cases you want to keep.
Timezones: Make sure everything is aligned. If one asset is in UTC and the other in NY time, your joins and indicators will lie to you.
Then, bring all your data into a standard format. It doesn’t matter if it’s pandas, parquet, SQL, or DuckDB, what matters is consistency. Every asset should have the same columns (open, high, low, close, volume, features, targets) with the same naming and structure.
Finally, create a simple way to access this data. If it takes 5 minutes to load a dataset, you won’t iterate. If your features live in 12 different files, you’ll lose track.
My tip: Take time to build once. Use everywhere, for backtest, validation, and later for live.
3. Setting Up the Modeling Pipeline (if ML is involved)
If your strategy relies on a machine learning model, this is the moment to get it ready.
You’re not training or evaluating yet, just setting things up.
Define your inputs and outputs
Choose your model architecture (classifier, regressor, LSTM…)
Make sure the model can consume your current feature format
This step ensures that when you get to the next phase, strategy design, you won’t waste time building models from scratch. Everything is in place and reproducible.
If your strategy doesn’t use ML, that’s fine. This step is optional. But if it does, don’t skip it. A working model pipeline is the foundation of repeatable research.
4. Final Checklist: Ready for Strategy Building?
Before moving on, you need to be sure everything is in place.
Ask yourself:
Are all my features aligned with the target and its horizon?
Could I reproduce this setup in a live environment without surprises?
Is my data pipeline solid, clean, and reusable?
If the answer is yes, you’re ready.
Next step: turning this prepared data into an actual strategy. Entry, exit, risk management, that’s what we’ll tackle in the next newsletter.
👉 If you want to go deeper into each step of the strategy building process, with real-life projects, ready-to-use templates, and 1:1 mentoring, that’s exactly what the Alpha Quant Program is for.
It’s the full roadmap I use to turn ideas into live strategies.